
之前我論文口試的時候,被口試委員問到:「你估測的都是連續影像,為什麼你的類神經網路辨識結果這麼不穩定?每一個 frame 跳動都這麼大?」
口委看的是這些圖和影片:
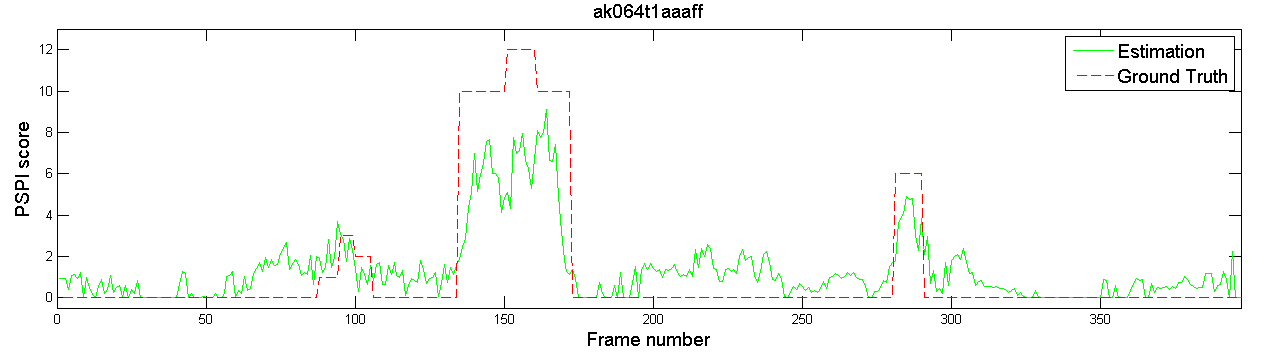
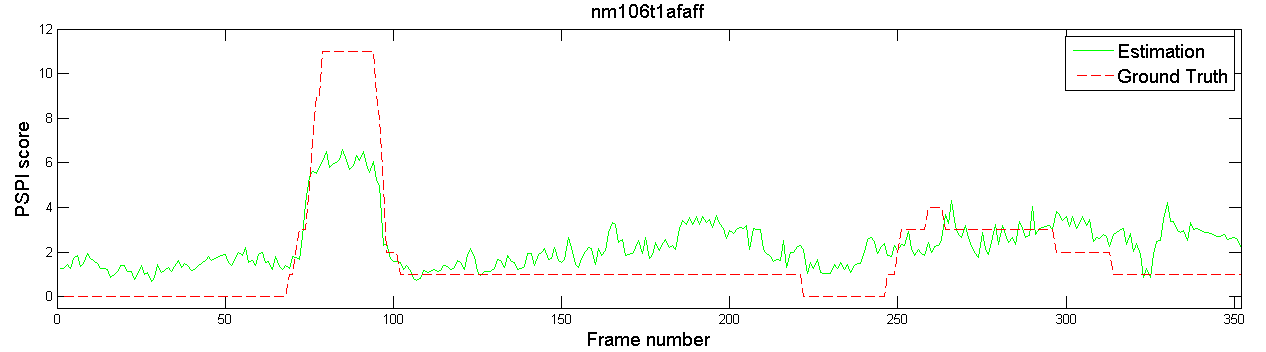
那我怎麼回答?當時沒辦法給一個很好的答案,只能說:
- 大概是樣本不平衡
- 與之比較的優秀文獻實驗結果也是這樣
文獻截圖:
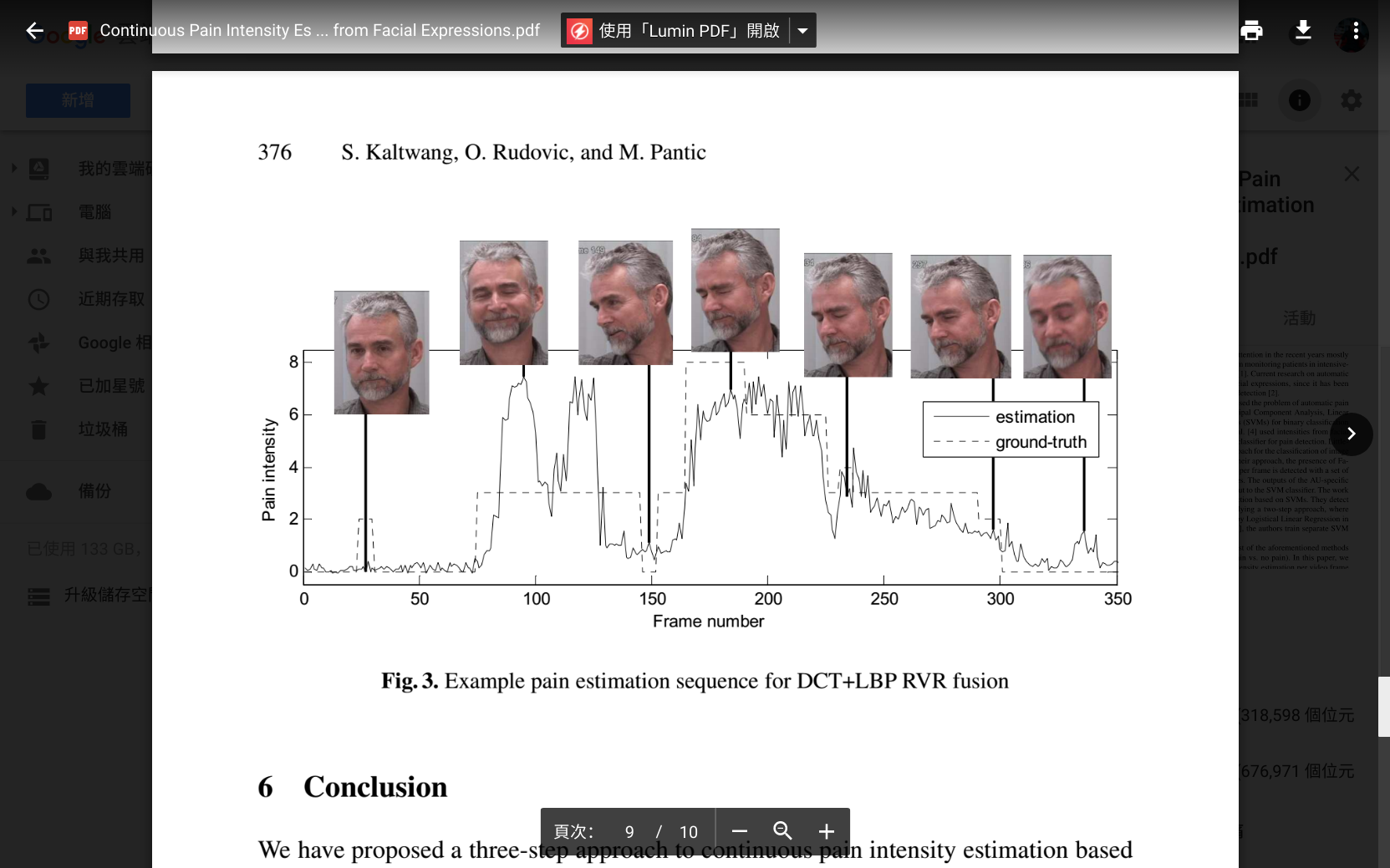
我對以上回答,其實沒什麼信心。
今天正好發現一篇文章,說明這是一個普遍現象,而且有給出普遍性的幾合解釋:針對機器學習的惡意資料攻擊(一)
最早是 Szegedy et al(2013) 發現對於用 ImageNet、AlexNet 等資料集訓練出來的影像辨識模型,常常只需要輸入端的微小的變動,就可以讓輸出結果有大幅度的改變。例如取一張卡車的照片,可以被模型正確辨識,但只要改變影像中的少數像素,就可以讓模型辨識錯誤,而且前後對影像的改變非常少,對肉眼而言根本分不出差異。
原來是 2013 年就有的研究阿!要是我早點知道就好了。
你以為這樣就結束了嗎?還沒。
文中給的幾何解釋是這樣:
在 Goodfellow et al(2014) 是這樣解釋的:線性的計算基本上就是像 z=wx+b 這樣的步驟,其中 w 與 b 是 weight 與 bias,x 是 input,z 是 stimulation,w 與 x 都是向量,wx 是向量內積。因此當 d 與 w 平行時,z’=w(x+d)+b=wx+wd+b 可以因為一個微小的變動 d 產生很大的輸出結果改變(wd 很大)。當這些向量的維度很高(即 model feature 很多)的時候,wd 就可以大到造成誤判。
這個現象我們都知道,所以才要先對資料集作正規化,不是嗎?
文章裡又說到:
這個看法可以得出幾個結果:
這解釋了過去用的 regularization 手法例如 dropout、pretraining、model average 防堵攻擊的效果不大。
但此處說的 regularization 手法都是對 model,不是對 data,所以這個解釋依舊無法讓我完全釋懷。